- Admissions
- Academics
- Research Office
- Student Life
- News & Events
- Outreach
- About
Hani Saleh is an associate professor of electronic engineering at Khalifa University since 2017, he joined Khalifa as an assistant professor in 2012. He is a co-founder of the KSRC (Khalifa University Research Center 2012-2018), moreover, he is a co-founder and a theme-lead in the System on Chip Research Center (SOCC 2019-present) where he led multiple IoT projects for the development of wearable blood glucose monitoring SOC, mobile surveillance SOC, and AI Accelerators for edge devices. Hani has a total of 19 years of industrial experience in ASIC chip design, Microprocessor/Microcontroller design, DSP core design, Graphics core design, and embedded systems design.
Prior to joining Khalifa University, he worked for many leading semiconductor design companies including Apple incorporation, Intel (ATOM mobile microprocessor design), AMD (Bobcat mobile microprocessor design), Qualcomm (QDSP DSP core design for mobile SOCs), Synopsys (designed the I2C DW IP included in Synopsys DesignWare library), Fujitsu (SPARC compatible high-performance microprocessor design) and Motorola Australia.

Artificial Intelligence (AI) engines have been integrated into a myriad of applications, whether they run in data centers or on edge/end-node devices. Most contemporary AI applications use the cloud to execute computationally intensive and power-demanding deep learning algorithms. Moving the processing from the cloud to edge devices reduces data transfers and latency, improves security, and enables scalability. The huge computational requirements of deep learning neural networks (DNN) deem it necessary to achieve challenging tradeoffs among energy, latency, and accuracy, at every application level. This project will utilize alternative numbering systems and fused primitives to create DNN architectures with low latency, low energy, and high accuracy for AI implementation. Optimization at the algorithm and architecture level will enable the proposed architectures to attain target power and performance, moreover, optimized digital circuit primitives for functions that accelerate AI engines in FPGAs and ASICs will be developed, verified, and demonstrated in FPGA prototypes.
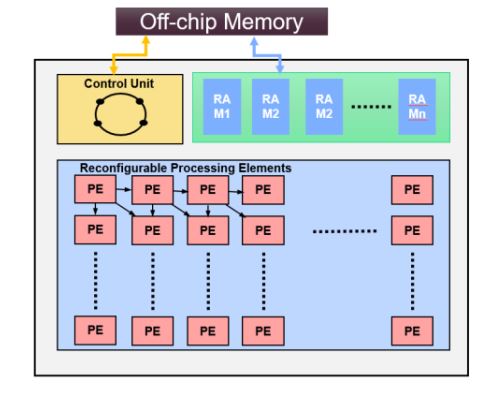
This project aims to achieve power-efficient and scalable AI architectures through the following
approaches.
RNS for AI
As in every digital application, the number representation scheme utilized in realizing AI architectures
directly impacts the accuracy, speed, area, and energy dissipation. It affects the way the hardware
implements all algorithmic operations and influences the complexity and utilization of the PE, the
required memory space, and the bandwidth required for memory access. In this project, RNS will be
used to perform tensor operations, such as direct sum, and vector product, as well as the comparisons needed
for deep learning AI applications, targeting the exploitation of its inherent parallelism, dynamic range
flexibility, power efficiency, and high-speed properties.
