New model unlocks vision in robotics and wins Best Paper Award at one of the most prestigious and influential conferences in the field of computer vision
Robots are becoming increasingly involved in our everyday lives, lending their hands to everything from manufacturing and logistics to healthcare and housework. Yet, they face a significant hurdle: accurately recognizing and dividing up objects in their environment, a task made challenging by blockages, complex shapes, and ever-changing backgrounds. This stands in the way of them fully grasping the world around them, limiting their abilities and efficiency.
The technical term for this daunting task is ‘panoptic segmentation’ — dividing an image into foreground objects and background regions simultaneously. If robots could master this skill, their perception of the environment would greatly improve, enabling them to handle more complex tasks efficiently.
However, this robotic vision problem isn’t easy to solve. Cluttered scenes, object variability, occlusions (objects that block vision), motion blur, and slow temporal resolution of traditional cameras all conspire to make it a tough nut to crack. Added to this, high latency—or delays—in processing sensor data can slow down response times and reduce task accuracy. The latest developments in object segmentation using cutting-edge Graph Neural Networks have their own limitations; they add extra requirements as both panoptic segmentation and grasp planning must be done quickly and efficiently. More sophisticated algorithms and techniques that can grapple with the real world’s unpredictability and complexity are needed.
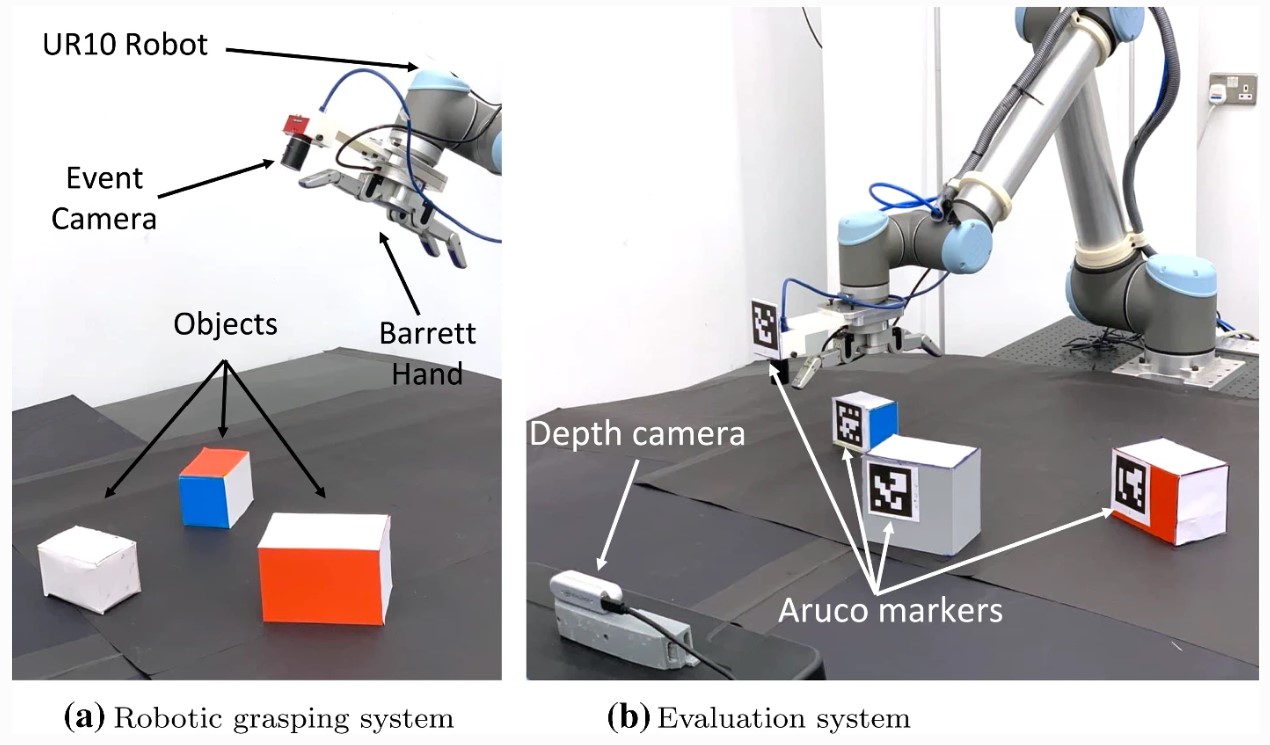
Dr. Yusra Alkendi, PhD student, and Dr. Yahya Zweiri, Professor and Director of the KU Advanced Research and Innovation Center, developed a method to overcome these challenges using a Graph Mixer Neural Network (GMNN). Specifically designed for event-based panoptic segmentation, a GMNN preserves the asynchronous nature of event streams, making use of spatiotemporal correlations to make sense of the scene. The KU researchers developed their solution with Sanket Kachole, Fariborz Baghaei Naeini and Dmitirios Makris from Kingston University and showcased their results at the IEEE Conference on Computer Vision and Pattern Recognition, one of the most prestigious and influential conferences in the field of computer vision. Here, they were awarded Best Paper by a distinguished committee that included experts from Meta, Intel, and leading U.S. universities.
The linchpin of their solution is the novel Collaborative Contextual Mixing (CCM) layer within the graph neural network architecture. This allows for the simultaneous blending of event features generated from multiple groups of neighborhood events. They also based their solution on event cameras, also known as dynamic vision sensors, which respond to local changes in brightness, with each pixel operating independently and asynchronously. The changes in brightness are reported as they occur and time-stamped with high temporal precision, providing precise information about when the change occurred, enabling the camera to capture fast and dynamic scenes accurately, including rapid motion and high-frequency events.
A dynamic vision sensor merges the cutting-edge CCM technique with an established neural network, with the new setup simultaneously processing events at multiple levels, leading to parallel feature learning —or high-speed multi-tasking for robots.
This architecture works by the encoder performing “downsampling” operations (reducing data) while the decoder carries out “upsampling” operations (increasing data) on events. The outcome is an effective panoptic segmentation model that’s particularly useful for robotic grasping.
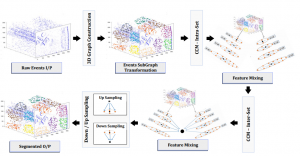
Proposed Framework – Graph Mixer Neural Network (GMNN) for panoptic segmentation of asynchronous event data in a robotic environment.
GMNN operates on a 3D- graph constructed of DVS events acquired within a temporal window, encapsulating its spatiotemporal properties. Subgraphs of
spatiotemporally neighboring events are then constructed (colored event in step 2) where each is processed by various nonlinear operations within Mixer and sampling modules to perform segmentation
The team tested their proposed model on an event-based segmentation dataset (ESD) under a wide range of conditions. Its success demonstrated the robustness of the novel CCM approach in overcoming obstacles like low lighting, small objects, high speed, and linear motion. The faster prediction times offered by the model is a leap in the quest to enable robots to process their environment faster and more accurately.
“GMNN has proven its worth, achieving top performance on the ESD dataset, a collection of robotic grasping scenes captured with an event camera positioned next to a robotic arm’s gripper,” Dr. Zweiri said. “This data contained a wide range of conditions: variations in clutter size, arm speed, motion direction, distance between the object and camera, and lighting conditions. GMNN not only achieves superior results in terms of its mean Intersection Over Union (a key metric for segmentation accuracy) and pixel accuracy, but it also marks significant strides in computational efficiency compared to existing methods.”
This model lays the groundwork for a future where robots can perceive and interact with their environment as efficiently as possible, opening up a world of potential applications across various industries. Future research will investigate the extent to which this new approach can be generalized in real-world scenarios with a variety of robots, sensors and environments, including depth sensors or thermal cameras, which could boost the model’s performance in low-light conditions.
Jade Sterling
Science Writer
05 July 2023